











网络营销新知:DeepSeek是什么?AI时代的新篇章或即将翻开
2025 / 02 / 12
AI网络技术高速发展的时代,人工智能(AI)已经渗透到我们生活的方方面面,从智能家居到自动驾驶,从聊天机器人到医疗诊断,AI技术正以前所未有的速度改变着世界。
而在这场AI技术革命中,DeepSeek,一家成立于2023年的中国AI公司,正以其独特的「通用人工智能」(AGI)愿景和先进的技术实力,引起业界的广泛关注。
那么,DeepSeek是什么?它是否真的有能力开启AI时代新篇章?
网络营销新知:什么是DeepSeek?
DeepSeek是一款基于深度学习和数据挖掘技术的智能搜索与分析系统,由中国的深度求索(DeepSeek Inc.)公司自主研发,主要利用深度神经网络(DNN)对数据进行建模,能够自动提取数据的特征,并理解数据之间的复杂关系。
这种模型特别适用于处理非结构化数据(如文本、图像和音频等),通过理解用户意图、上下文以及多模态数据,提供精准、高效和个性化的搜索结果和推荐服务。目前DeepSeek在多个领域展现出了巨大的应用潜力,它不仅能够实现智能化的搜索与分析,还能够根据用户的需求和偏好,提供定制化的解决方案。
DeepSeek的技术核心是「大语言模型(LLM)」,类似于OpenAI的GPT或Google的BERT,但他们更专注于实现AGI(Artificial General Intelligence),让AI变得更通用、更智能。此外,DeepSeek还使用了以下技术,确保电脑在处理大量资料时,能够更省记忆体、更快运算,并且适合处理复杂的任务:
○ Multi-head Latent Attention (MLA):通过「低秩因子分解(Low-Rank Factorization)」技术,减少需要记忆的数据量,使电脑在处理大量数据时能够降低内存使用,并加快处理速度。
○ MoE(混合专家)架构:这种技术让电脑在处理任务时无需动用全部资源,只需启动关键部分即可工作,从而显著提升处理速度。
○ FP8混合精度训练框架:相比传统的FP16和FP32,FP8能够更节省内存,使训练和推理的速度更快、效率更高。
○ DualPipe技术:在多个GPU之间传输数据时,DualPipe技术能够确保数据传输更加顺畅,减少等待时间,提升整体效率。
网络营销新知:DeepSeek-V3、DeepSeek-R1的比较
DeepSeek于2024年底发布全新AI大语言模型DeepSeek-R1、DeepSeek-V3,并在2025年1月发布DeepSeek-R1的聊天机器人程式。虽然两者是同胞兄弟,但是无论是定位、架构,还是性能及应用场景上都存在显著差异:
① 模型定位与核心能力对比
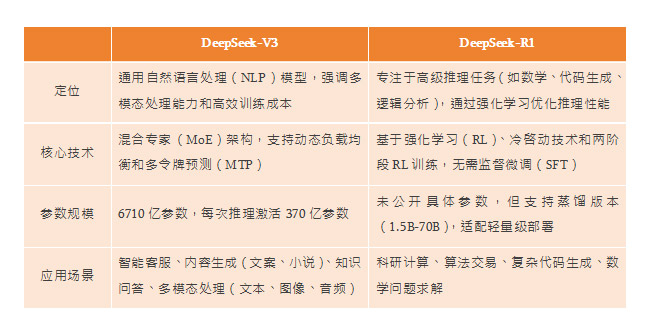
② 模型架构与技术差异
● 架构设计
DeepSeek-V3:采用混合专家(MoE)架构,通过智能路由系统动态激活专家模块(如编程语言专家或文本摘要专家),结合多头潜在注意力(MLA)提升效率。
DeepSeek-R1:基于V3的架构优化,引入 动态门控机制 和强化学习框架(如 GRPO 算法),专门针对推理任务调整专家激活策略。
● 训练方法
V3:传统预训练-微调范式,结合 FP8 混合精度训练和并行优化,训练成本仅为 GPT-4 的 1/20。
R1:完全依赖 强化学习(RL),通过大规模 RL 和冷启动技术激发推理能力,减少对标注数据的依赖。
③ 性能与基准测试对比

④ 应用部署与生态支持
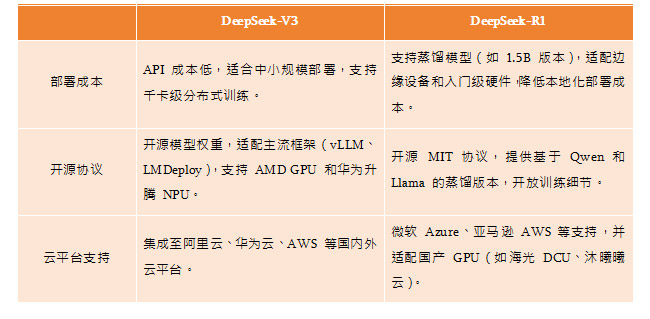
总体来说,两款模型均通过算法优化降低了成本,且开源生态推动了 AI 技术的普惠化。
但DeepSeek-V3满足各种通用NLP任务(如文本生成、多模态处理),追求高性价比和广泛兼容性;而DeepSeek-R1则适用于需解决复杂逻辑推理(如数学证明、代码生成)或需轻量级本地部署的场景,用户可根据具体需求灵活组合使用。
未完待续……
而在这场AI技术革命中,DeepSeek,一家成立于2023年的中国AI公司,正以其独特的「通用人工智能」(AGI)愿景和先进的技术实力,引起业界的广泛关注。
那么,DeepSeek是什么?它是否真的有能力开启AI时代新篇章?
网络营销新知:什么是DeepSeek?
DeepSeek是一款基于深度学习和数据挖掘技术的智能搜索与分析系统,由中国的深度求索(DeepSeek Inc.)公司自主研发,主要利用深度神经网络(DNN)对数据进行建模,能够自动提取数据的特征,并理解数据之间的复杂关系。
这种模型特别适用于处理非结构化数据(如文本、图像和音频等),通过理解用户意图、上下文以及多模态数据,提供精准、高效和个性化的搜索结果和推荐服务。目前DeepSeek在多个领域展现出了巨大的应用潜力,它不仅能够实现智能化的搜索与分析,还能够根据用户的需求和偏好,提供定制化的解决方案。
DeepSeek的技术核心是「大语言模型(LLM)」,类似于OpenAI的GPT或Google的BERT,但他们更专注于实现AGI(Artificial General Intelligence),让AI变得更通用、更智能。此外,DeepSeek还使用了以下技术,确保电脑在处理大量资料时,能够更省记忆体、更快运算,并且适合处理复杂的任务:
○ Multi-head Latent Attention (MLA):通过「低秩因子分解(Low-Rank Factorization)」技术,减少需要记忆的数据量,使电脑在处理大量数据时能够降低内存使用,并加快处理速度。
○ MoE(混合专家)架构:这种技术让电脑在处理任务时无需动用全部资源,只需启动关键部分即可工作,从而显著提升处理速度。
○ FP8混合精度训练框架:相比传统的FP16和FP32,FP8能够更节省内存,使训练和推理的速度更快、效率更高。
○ DualPipe技术:在多个GPU之间传输数据时,DualPipe技术能够确保数据传输更加顺畅,减少等待时间,提升整体效率。
网络营销新知:DeepSeek-V3、DeepSeek-R1的比较
DeepSeek于2024年底发布全新AI大语言模型DeepSeek-R1、DeepSeek-V3,并在2025年1月发布DeepSeek-R1的聊天机器人程式。虽然两者是同胞兄弟,但是无论是定位、架构,还是性能及应用场景上都存在显著差异:
① 模型定位与核心能力对比
② 模型架构与技术差异
● 架构设计
DeepSeek-V3:采用混合专家(MoE)架构,通过智能路由系统动态激活专家模块(如编程语言专家或文本摘要专家),结合多头潜在注意力(MLA)提升效率。
DeepSeek-R1:基于V3的架构优化,引入 动态门控机制 和强化学习框架(如 GRPO 算法),专门针对推理任务调整专家激活策略。
● 训练方法
V3:传统预训练-微调范式,结合 FP8 混合精度训练和并行优化,训练成本仅为 GPT-4 的 1/20。
R1:完全依赖 强化学习(RL),通过大规模 RL 和冷启动技术激发推理能力,减少对标注数据的依赖。
③ 性能与基准测试对比
④ 应用部署与生态支持
总体来说,两款模型均通过算法优化降低了成本,且开源生态推动了 AI 技术的普惠化。
但DeepSeek-V3满足各种通用NLP任务(如文本生成、多模态处理),追求高性价比和广泛兼容性;而DeepSeek-R1则适用于需解决复杂逻辑推理(如数学证明、代码生成)或需轻量级本地部署的场景,用户可根据具体需求灵活组合使用。
未完待续……
更多文章
-

生成式 AI 搜索也能卖广告?解密 Google AIO 广告与传统 Google Ads 有何不同
2026/07/15 本文將全面揭秘 AIO 原生廣告與傳統 Google Ads 的核心差異,並提供最新的 AIO 廣告投放技巧及 GEO 優化技巧,助您搶佔生成式 AI 廣告的黃金版位! -

社媒营销策略全攻略:IG Reels与TikTok,品牌如何找出合适的获利模式
2026/07/07 IG Reels和TikTok备受全球年轻人追捧,香港中小企该如何选择?本文全面对比两者的算法、受众及转化率,助你与市场主管制定高效网络营销策略,拒绝盲目跟风,实现精准增长! -

流量暴跌30%的解药:Google AI搜索大改版,企业如何靠GEO逆袭?
2026/06/30 面对AI Overviews与全新AI Mode的深度集成,传统SEO正面临流量下滑冲击。本文将拆解Google三大AI搜索功能更新,并提供Web MCP与E-E-A-T实战四部曲,带领企业将零点击搜索危机转化为高转换的品牌护城河。
