











什么是robots.txt?详谈如何利用robots.txt阻止网站被搜索引擎索引
2023 / 08 / 25
对绝大多数商家而言,「网站能够在搜索结果页中获得靠前排名,借此实现更可观的流量及转换」是他们进行网站SEO优化的目的。话虽如此,但是如果网站有些「不可告人的秘密」,而又不想让Google、Yahoo等搜索引擎爬虫爬时,我们又有什么方法可以阻止它们的行动呢?
也就是说,robots.txt相当于网站提供给爬虫的「访问须知」或「交通指示牌」,并具有以下内核作用:
• 允许或禁止抓取:指引特定爬虫访问或避开某些目录与文件。
• 管理爬虫流量:避免不重要、无限循环或私密页面被爬取,节省服务器资源与爬虫预算。
•指定网站地图:通过Sitemap指令,告知爬虫XML网站地图的位置,帮助它们更有效率地索引内容。
如果你希望搜索引擎爬虫可以更快地发现网站的新页面,也可以设置一个完全开放的 robots.txt文件,并在其中提交Sitemap位置,主动邀请爬虫进行抓取。
反之,如果你的网站页面不多,且所有内容都是公开的,那么不设置robots.txt也无妨,这代表缺省对所有爬虫开放。例如单页式网站,如果没有需要屏蔽的部分,不设置robots.txt也是常见做法。
如何为网站设置robots.txt?基础规则一次看懂
Step 1 搞清robots.txt文档的基本规则
一般来说,robots.txt文档会包含以下这些指令:
• user-agent:指定规则适用的搜索引擎检索器名称,其中星号(*)通常表示适用除指定搜索引擎检索器以外的所有搜索引擎检索器。
• disallow:禁止前述搜索引擎检索器在根网域下检索特定的目录或网页。
• allow:允许前述搜索引擎检索器在根网域下检索特定的目录或网页。
• sitemap:告知搜索引擎检索器,该网站的Sitemap所在位置。
值得注意的是,每项规则至少要有一个disallow或allow项目。
以下枚举几种实用设置范例:
Step 2 了解robots.txt文件的设置限制
在创建或编辑robots.txt文件之前,建议先了解以下关于网址封锁方式的限制,网站管理员可以视乎网站目标和状况而改用其他机制,以确保无人能通过网络搜索到你的网址:
① 并非所有搜索引擎都支持robots.txt规则
虽然大部分搜索引擎检索器都会遵循robots.txt文件中的指示,但并非每个检索器都是如此,因此若要确保特定信息不会被检索器访问,建议使用其他方式(如使用密码保护服务器上的私人文件等)来封锁搜索引擎检索器的访问。
② 各种检索器解读语法的方式有所不同
虽然大部分搜索引擎检索器都会遵循robots.txt文件中的规则,但各个检索器解读规则的方式可能有所不同,部分搜索引擎检索器可能无法理解特定的指示,因此网站管理员需要掌握不同检索器的robots.txt规则并采用合适的语法。
③ 如果其他网站链接到robots.txt所封锁的网页,检索器仍然可以为其创建索引
虽然搜索引擎检索器通常不会对robots.txt所封锁的内容进行检索或创建索引,但如果封锁网页于网络上其他网页出现,检索器仍然会创建这些网址的索引,甚至在搜索结果中显示。如要完全避免这种建议,建议使用密码保护服务器上的文件、使用noindex meta标记或回应标头,或完全移除网页等。
Step 3 测试robots.txt是否正常
正常来说,当你将robots.txt文件保存在网站根目录中后,搜索引擎检索器就会自动寻找并开始使用robots.txt文件。但需要注意的是,为了保证robots.txt文件能够被检索器正常访问,文件上传后别忘记使用「robots.txt 测试工具进行检测」:

△ 登录https://www.google.com/webmasters/tools/robots-testing-tool,选择你需要测试的验证的网址。
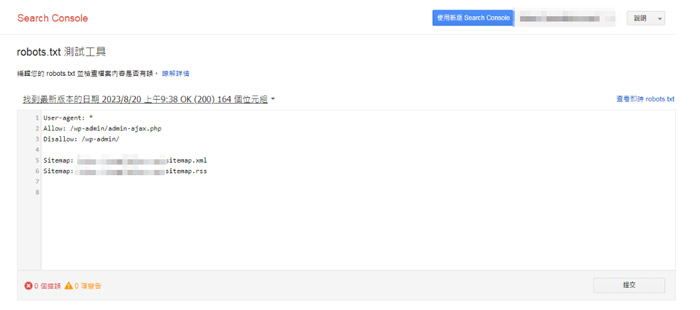
△ 接着就可以测试当前robots.txt文件是否有问题,以及查看即时robots.txt的文件内容。
反之,如果网站错误使用robots.txt文件来阻止搜索引擎检索器来做索引,那肯定是对网站SEO成效大打折扣。因此,网站架构初期一定要谨慎,否则第一步走错,后续的影响绝对是很深远的。
香港网页提供一站式数码营商方案服务,包括、网页设计、网络推广、网页管理与寄存、系统开发及其它增值服务,全方位满足客户的业务需要,欢迎随时联系我们,香港网页是您开拓网络商机的最佳伙伴。
联系电话:852-3749 9734
电邮地址:[email protected]
网址:https://hkweb.com.hk
什么是robots.txt?不想让搜索引擎发现页面的秘诀
robots.txt是一个放置于网站根目录下的纯文本文件(如https://www.example.com/robots.txt),主要用于与网络爬虫(如搜索引擎的爬虫程序)进行沟通,指示哪些内容允许抓取、哪些应予避开。
也就是说,robots.txt相当于网站提供给爬虫的「访问须知」或「交通指示牌」,并具有以下内核作用:
• 允许或禁止抓取:指引特定爬虫访问或避开某些目录与文件。
• 管理爬虫流量:避免不重要、无限循环或私密页面被爬取,节省服务器资源与爬虫预算。
•指定网站地图:通过Sitemap指令,告知爬虫XML网站地图的位置,帮助它们更有效率地索引内容。
是不是所有网站都需要设置robots.txt?未必!
网站是否需要设置robots.txt文档往往取决于其实际需求与目标,如果网站存在不希望被收录的内容,例如登录/注册页面、后台接口、站内搜索结果以及特定类型的文档等,就可以通过robots.txt限制爬虫访问,确保搜索引擎将「抓取预算」集中在重要页面,提升索引效率。如果你希望搜索引擎爬虫可以更快地发现网站的新页面,也可以设置一个完全开放的 robots.txt文件,并在其中提交Sitemap位置,主动邀请爬虫进行抓取。
反之,如果你的网站页面不多,且所有内容都是公开的,那么不设置robots.txt也无妨,这代表缺省对所有爬虫开放。例如单页式网站,如果没有需要屏蔽的部分,不设置robots.txt也是常见做法。
如何为网站设置robots.txt?基础规则一次看懂
Step 1 搞清robots.txt文档的基本规则一般来说,robots.txt文档会包含以下这些指令:
• user-agent:指定规则适用的搜索引擎检索器名称,其中星号(*)通常表示适用除指定搜索引擎检索器以外的所有搜索引擎检索器。
• disallow:禁止前述搜索引擎检索器在根网域下检索特定的目录或网页。
• allow:允许前述搜索引擎检索器在根网域下检索特定的目录或网页。
• sitemap:告知搜索引擎检索器,该网站的Sitemap所在位置。
值得注意的是,每项规则至少要有一个disallow或allow项目。
以下枚举几种实用设置范例:
| 情境 | 范例 | 说明 |
|---|---|---|
| 禁止所有爬虫抓取整个网站 | User-agent: *Disallow: / |
注意:未被抓取的网址仍可能被索引。 |
| 禁止抓取特定目录 | User-agent: *Disallow: /private/Disallow: /temp/ |
目录名称后加 / 表示整个目录。 |
| 仅允许特定爬虫抓取 | User-agent: Googlebot-newsAllow: /User-agent: *Disallow: / |
只开放给 Google 新闻爬虫。 |
| 禁止抓取特定文件类型 | User-agent: GooglebotDisallow: /*.pdf$ |
使用 $ 匹配特定结尾的网址。 |
| 禁止 Google 图片索引所有图片 | User-agent: Googlebot-ImageDisallow: / |
适用于避免图片出现在图片搜索结果。 |
Step 2 了解robots.txt文件的设置限制
在创建或编辑robots.txt文件之前,建议先了解以下关于网址封锁方式的限制,网站管理员可以视乎网站目标和状况而改用其他机制,以确保无人能通过网络搜索到你的网址:
① 并非所有搜索引擎都支持robots.txt规则
虽然大部分搜索引擎检索器都会遵循robots.txt文件中的指示,但并非每个检索器都是如此,因此若要确保特定信息不会被检索器访问,建议使用其他方式(如使用密码保护服务器上的私人文件等)来封锁搜索引擎检索器的访问。
② 各种检索器解读语法的方式有所不同
虽然大部分搜索引擎检索器都会遵循robots.txt文件中的规则,但各个检索器解读规则的方式可能有所不同,部分搜索引擎检索器可能无法理解特定的指示,因此网站管理员需要掌握不同检索器的robots.txt规则并采用合适的语法。
③ 如果其他网站链接到robots.txt所封锁的网页,检索器仍然可以为其创建索引
虽然搜索引擎检索器通常不会对robots.txt所封锁的内容进行检索或创建索引,但如果封锁网页于网络上其他网页出现,检索器仍然会创建这些网址的索引,甚至在搜索结果中显示。如要完全避免这种建议,建议使用密码保护服务器上的文件、使用noindex meta标记或回应标头,或完全移除网页等。
Step 3 测试robots.txt是否正常
正常来说,当你将robots.txt文件保存在网站根目录中后,搜索引擎检索器就会自动寻找并开始使用robots.txt文件。但需要注意的是,为了保证robots.txt文件能够被检索器正常访问,文件上传后别忘记使用「robots.txt 测试工具进行检测」:
△ 登录https://www.google.com/webmasters/tools/robots-testing-tool,选择你需要测试的验证的网址。
△ 接着就可以测试当前robots.txt文件是否有问题,以及查看即时robots.txt的文件内容。
【最后】robots.txt对SEO优化重要吗?
答案并非绝对!首先我们需要搞清楚一点的是,robots.txt文件并不是每个网站必备的。Googlebot造访网站时,通常会先尝试截取 robots.txt 文件,寻求检索权限;如果网站没有设置robots.txt文件,或者是robots meta标记、X-Robots-Tag HTTP标头,Googlebot同样会对该网站进行检索并为创建索引,但有可能会增加检索预算(Crawl Budget)的浪费。反之,如果网站错误使用robots.txt文件来阻止搜索引擎检索器来做索引,那肯定是对网站SEO成效大打折扣。因此,网站架构初期一定要谨慎,否则第一步走错,后续的影响绝对是很深远的。
香港网页提供一站式数码营商方案服务,包括、网页设计、网络推广、网页管理与寄存、系统开发及其它增值服务,全方位满足客户的业务需要,欢迎随时联系我们,香港网页是您开拓网络商机的最佳伙伴。
联系电话:852-3749 9734
电邮地址:[email protected]
网址:https://hkweb.com.hk
更多文章
-

生成式 AI 搜索也能卖广告?解密 Google AIO 广告与传统 Google Ads 有何不同
2026/07/15 本文將全面揭秘 AIO 原生廣告與傳統 Google Ads 的核心差異,並提供最新的 AIO 廣告投放技巧及 GEO 優化技巧,助您搶佔生成式 AI 廣告的黃金版位! -

社媒营销策略全攻略:IG Reels与TikTok,品牌如何找出合适的获利模式
2026/07/07 IG Reels和TikTok备受全球年轻人追捧,香港中小企该如何选择?本文全面对比两者的算法、受众及转化率,助你与市场主管制定高效网络营销策略,拒绝盲目跟风,实现精准增长! -

流量暴跌30%的解药:Google AI搜索大改版,企业如何靠GEO逆袭?
2026/06/30 面对AI Overviews与全新AI Mode的深度集成,传统SEO正面临流量下滑冲击。本文将拆解Google三大AI搜索功能更新,并提供Web MCP与E-E-A-T实战四部曲,带领企业将零点击搜索危机转化为高转换的品牌护城河。
